my_ml_notes
Evaluating_LLMs
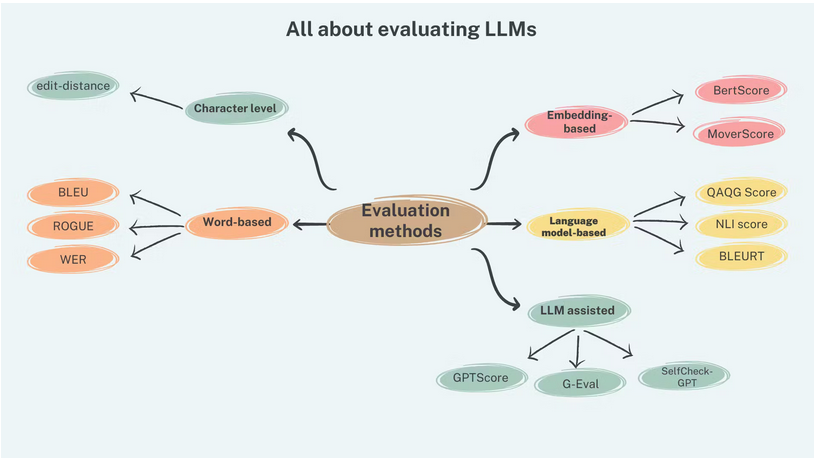
Ref. All about evaluating Large language models
Evaluating Embeddings
Ref. Amazon Bedrock: How good (bad) is Titan Embeddings?
Evaluating Models
TLTR:
-
Benchmarks does normaly not reflect business usecases but general knowledge.
-
GTP-4 is used as the judge -> thus certain bias is expected.
Building reliable benchmark for LLM chatbots is a challenge [ref. here]. Examples of challenges are:
- reflect human preference in real-work usecases
-
clearly identify/seperate model capabilities
- avoid overfitting/test set leakage
Below are some highlevel descriptions of some benchmarks for model evaluation:
MT-Bench
Arena Hard
Benchmark from live data from Chatbot Arena.
It contains 500 challenging user queries. GPT-4 is used as the judge to compare the models responses against a baseline model (GPT-4-0314)
See below some examples of questions used by the benchmark from here.
{"question_id":"1f07cf6d146d4038b2b93aaba3935ce0","category":"arena-hard-v0.1","cluster":"AI & Sequence Alignment Challenges","turns":[{"content":"Explain the book the Alignment problem by Brian Christian. Provide a synopsis of themes and analysis. Recommend a bibliography of related reading. "}]}
{"question_id":"379a490a6eae40608abf3501807b2545","category":"arena-hard-v0.1","cluster":"Advanced Algebra and Number Theory","turns":[{"content":" Consider the state:\n$$\\ket{\\psi} = \\frac{\\ket{00} + \\ket{01} + \\ket{10}}{\\sqrt{3}}$$\n\n(a). Calculate the reduced density matrix of the second qubit of $\\ket{\\psi}$."}]}
Evaluating RAG
LLM application evaluation is very important due to the nature of the non-deterministic behaviour of the models.
Every RAG evaluation need to consider the following components:
- Retriever: responsible for retrieval of most relevant information from the knowledge store to answer the query.
- Generator: responsible to generate a answer based on retrieved information.
The performance of the retriever is influeced by the chunking strategy and embedding model used, while the performance of the generator is influenced by the selection of the model and prompt technique.
RAGAS (Retrieval Augmented Generation Assessment)
Generation:
- faithfulness: the factual consistency of the answer to the context base on the question.
- answer_relevancy: a measure of how relevant the answer is to the question
Retrieval:
- context_precision: a measure of how relevant the retrieved context is to the question. Conveys quality of the retrieval pipeline.
- context_recall: measures the ability of the retriever to retrieve all the necessary information needed to answer the question.
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
Picture below is based on RAGAS - Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines. Re. AWS-Bedrock example here and blog to try here.

faithfulness (generation):
the factual consistency of the answer to the context base on the question. Performed in two step:
- step 1: given question and answer, LLM is used to create list of statements from answers.
- step 2: given the list of statements, LLM check if statement provided is supported by the context. Number of correct statement is summed and divided by total statements
answer_relevancy (generation):
a measure of how relevant the answer is to the question. It evaluates how closely the generated answer aligns with the initial question or instruction,
Given an answer the LLM find out the probable questions that the generated answer would be an answer to and computes similarity to the actual question asked.
The implementation looks like:
- Step 1: Generate a question(s) for the given answer
Generate a question for the given answer.
answer: [answer]
- Step 2: obtain embeddings for all questions using the text-embedding-ada-002 model from OpenAI.
- Step3: For each generated question, calculate similarity with the original question as cosine between the embeddings.
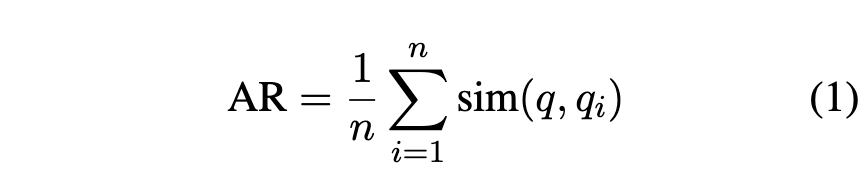
context_precision (retrieval):
a measure of how relevant the retrieved context is to the question. Conveys quality of the retrieval pipeline.
Also know as context relevancy, it measures the signal-to-noise ration in the retrieved contexts. Given a question, LLMs figure out sentences from the retrieved context that are needed to answer the question.
This metrics aims to penalise inclusion of redundant information. The steps used to calculate the metric are:
- step 1: Given a question q and its context c(q), LLM extracts a subset of sentences Sext from c(q) that are crucial to answer q using the prompt below.
Please extract relevant sentences from the provided context that can potentially help answer the following question. If no relevant sentences are found, or if you believe the question cannot be answered from the given context, return the phrase “Insufficient Information”. While extracting candidate sentences you’re not allowed to make any changes to sentences from given context
- step 2:
AWS FMEval and SageMaker Clarify (by Amazon)
Amazon SageMaker Clarify (SM Clarify) allows you to evaluate and compare foundation models. FMEval is the open source package for SageMaker Clarify.
FMEval/SM Clarify library can help to evaluate:
- Open-ended generation: production of natural human responses to text that does not have a pre-defined structure.
- Text summarization: generation of a concise and condensed summary while retaining the meaning and key information that’s contained in larger text.
- Question and answer: The generation of a relevant and accurate response to a prompt.
- Classification: Assigning a category, such as a label or score to text, based on its content.
It allows evaluation of models using automatic model evaluation and also human workers evaluation.
Automatic model evaluation metrics implemented by tool are:
- Accuracy: numerical score indicating the similarity of the summarization to a reference summary that is accepted as a gold standard. Accuracy of summarization uses the following metrics: ROUGE-N, Meteor, BERTScore. Accuracy of Q&A uses the following metrics: Exact match, quasi-exact-match, F1 over words
- Toxiticy: checks your model for sexual references, rude, unreasonable, hateful or aggressive comments, profanity, insults, flirtations, attacks on identities, and threats
- Semantic Robustness: how much your model output changes as the result of small, semantic-preserving changes in the input
- **Prompt Stereotyping: **probability of your model encoding biases in its response.
Human workers might evaluate your model for more subjective dimentions such as helpfullness or style.
Table below shows a summary of the metrics you can use for each tasks using FMEval.
| Tasks versus Metrics | Factual knowledge | Semantic robustness | Prompt stereotyping | Toxicity | Accuracy |
|---|---|---|---|---|---|
| Open-ended generation | x | x | x | x | - |
| Text summarization | - | x | - | x | x |
| Question and answer | - | x | - | x | x |
| Classification | - | x | - | x |
LightEval (By HuggingFace)
lighteval was originally built on top of the great Eleuther AI Harness (which is powering the Open LLM Leaderboard). We also took a lot of inspiration from the amazing HELM, notably for metrics.
Metrics:
Lanchain ContextQAEvalChain
Langchain Evaluation
LLMTest_NeedleInAHaystack
| Tool | Metrics | |
|---|---|---|
| RAGAS | Generation: faithfulness, answer_relevancy Retrieval: context precision, context recall |
|
| FMEval | Accuracy, Toxiticy, Semantic robustness, prompt stereotyping | |
Reference:
-
Paper: FELM: Benchmarking Factuality Evaluation of Large Language Models
-
Blog: Evaluate LLMs and RAG a practical example using Langchain and Hugging Face
-
LLM Evaluation using ML flow: https://mlflow.org/docs/latest/llms/llm-evaluate/index.html