my_ml_notes
Large Language Models
[TOC]
Background

Ref. from Yann Leccun video
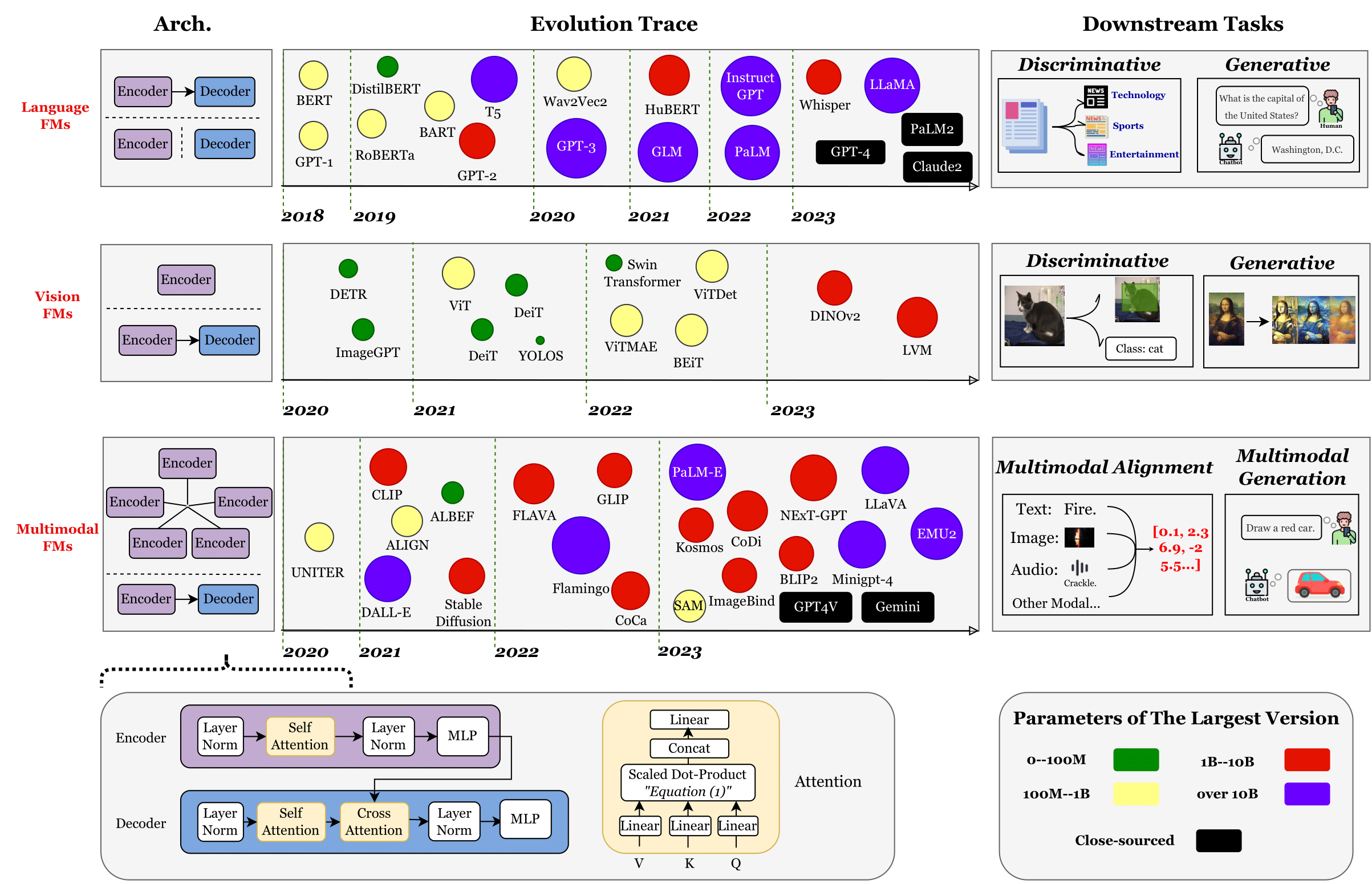
Figure by UbiquitousLearning/Efficient LLM and Foundation Models
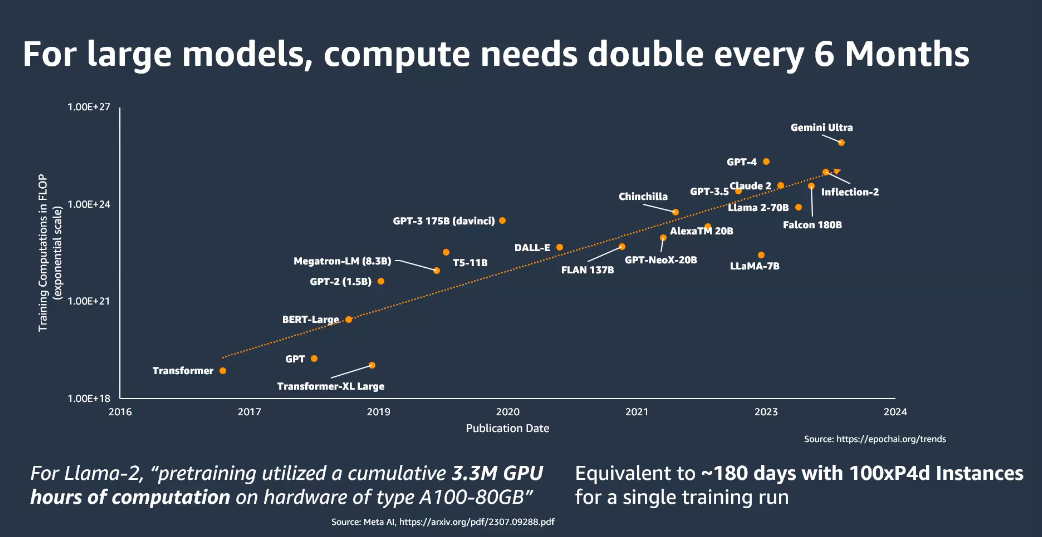
Picture from: Training Large Foundation Models Using SageMaker HyperPod by Ian Gibbs - Senior PMT-ES in AI/ML - Gen AI Enablement Weekly Series
1. Generative AI investment skyrockets
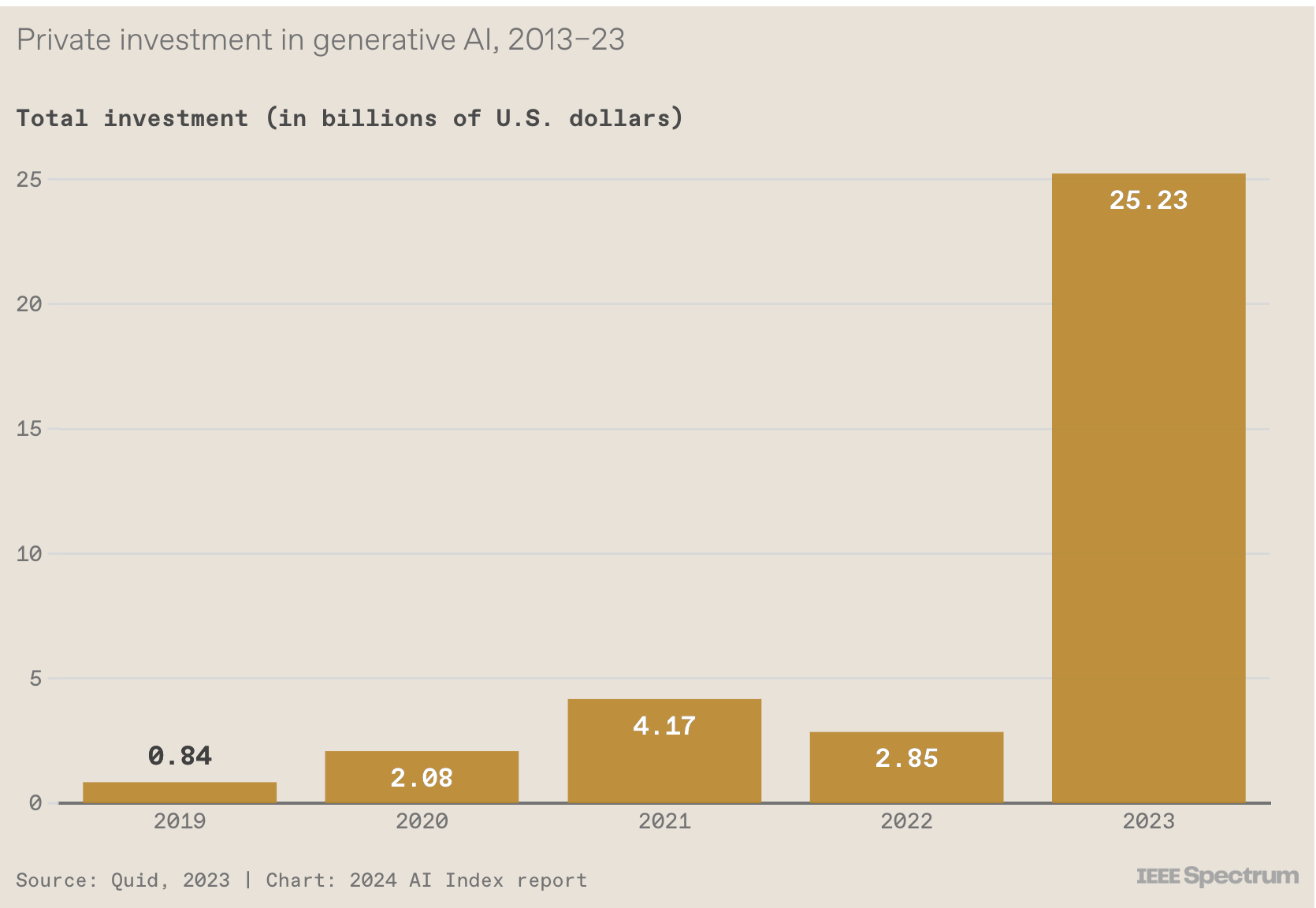
By IEEE Spectrum https://spectrum.ieee.org/ai-index-2024
LLM Models
Llama 3:
- https://github.com/meta-llama/llama3
- https://github.com/meta-llama/llama-recipes
- https://github.com/amitsangani/Llama/blob/main/Building_Using_Llama.ipynb
Prompt versus Fine Tune versus Pre-training
Guide to when to prompt versus fine tuning considering different organizations?
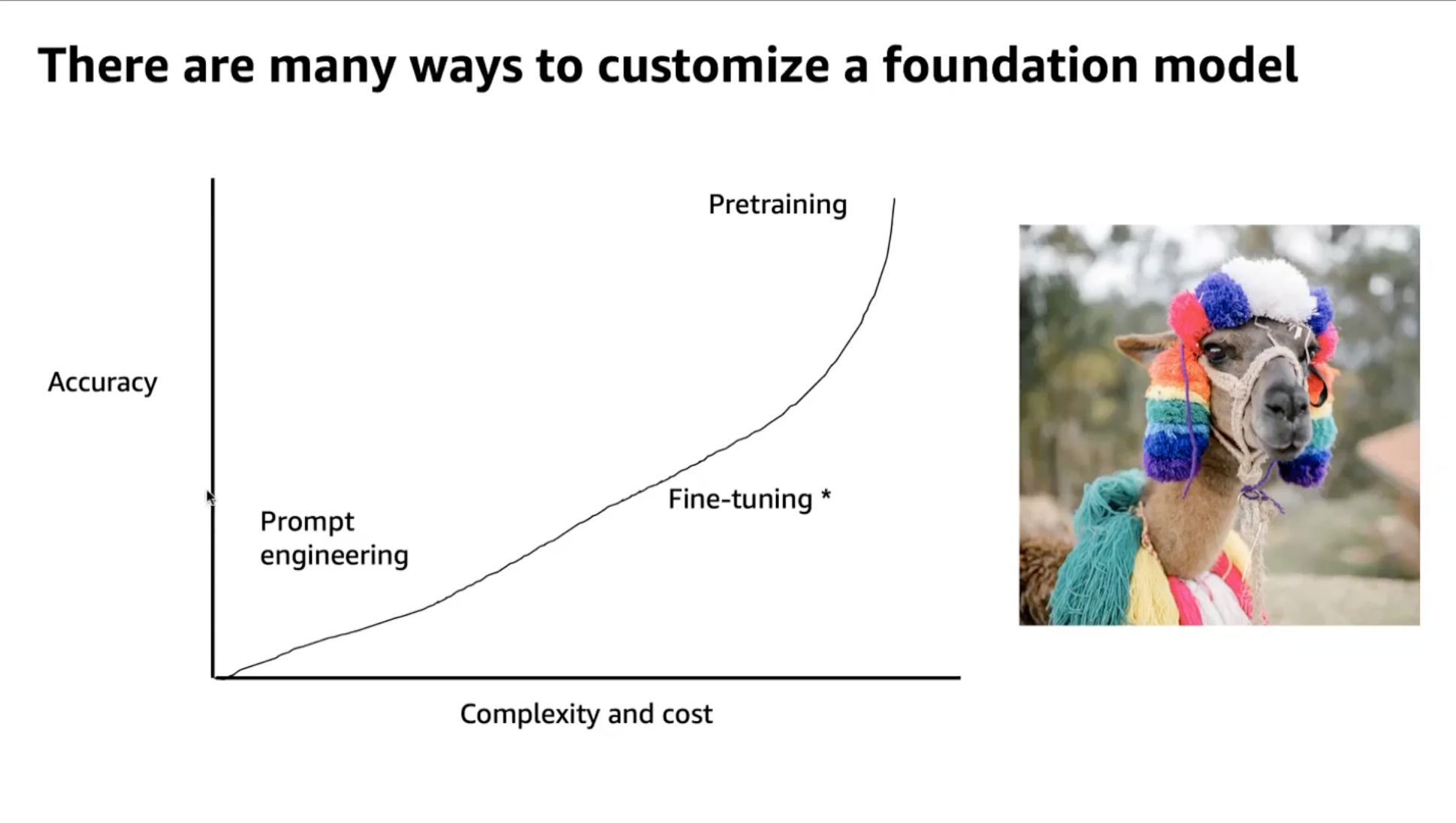
Parameter Efficient Fine Tuning
PEFT, or Parameter Efficient Fine-tuning, is a Hugging Face open-source library to enable efficient adaptation of pre-trained language models (PLMs) to various downstream applications without fine-tuning all the model’s parameters. PEFT currently includes techniques for:
-
Prefix Tuning: P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
-
P-Tuning: GPT Understands, Too
-
Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
-
IA3: Infused Adapter by Inhibiting and Amplifying Inner Activations
LoRA: Low-Rank Adaptation of LLMs
QLORA:
Reference:
[1] LoRA Serving on Amazon SageMaker — Serve 100’s of Fine-Tuned LLMs For the Price of 1
[3] Github example: Fine-tune LLaMA 2 on Amazon SageMaker
[4] GitHub example: Fine-tune LLaMA 2 models on SageMaker JumpStart
[6] Ref.scaling down to scale up a guide to parameter-efficient fine-tuning
[7] LoRA Paper
[8] LoRA Land: Fine-Tuned Open-Source LLMs that Outperform GPT-4
Price of Training LLMs
License
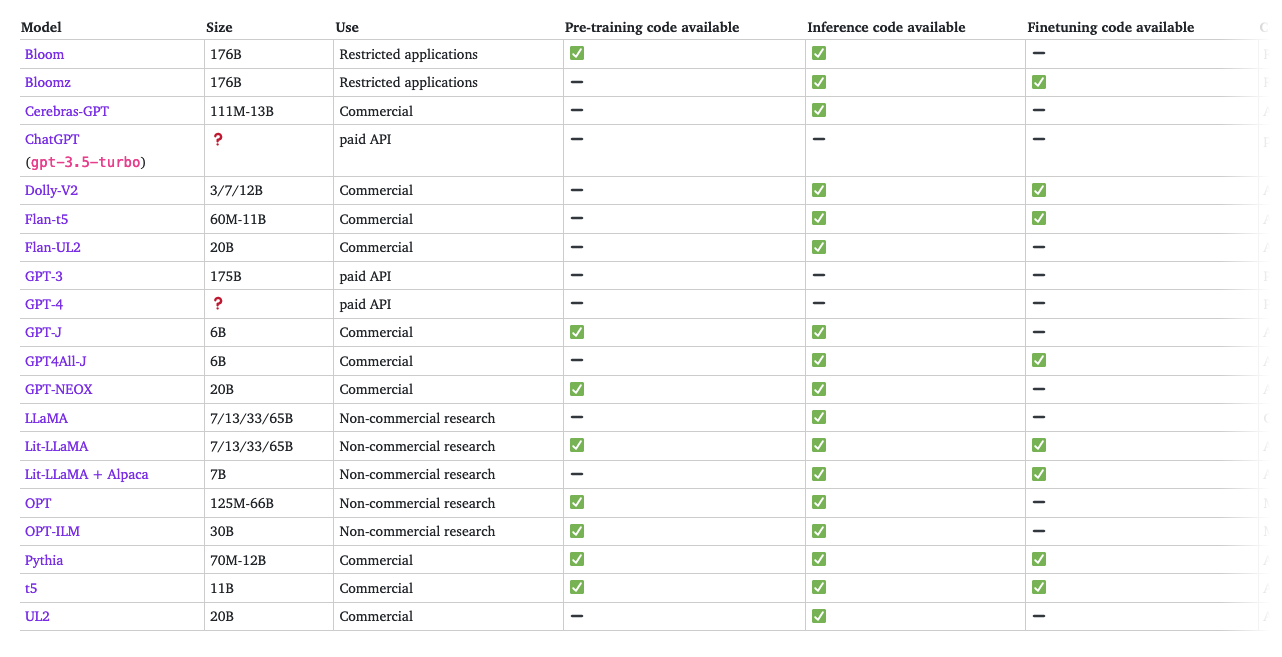
Ref. The Ultimate Battle of Language Models: Lit-LLaMA vs GPT3.5 vs Bloom vs …
Commercial versus Licensed Models in HuggingFace
RLHL: Reinforcement Learning Human in the Loop
Policy
Proximal Policy Optimization (PPO): reinforcement learing algorithm
Deepracer PPO:
Batch size:
-
number of experiences sampled at random from an experience buffer and used to update the neural network weights.
-
The batch is a subset of an experience buffer that is composed of images captured by the camera mounted on the AWS DeepRacer vehicle and actions taken by the vehicle.
Epochs:
- Number of passes through the trainning data to update the NN weights during the gradient descent
Learning rate:
- controls how much gradient descent update contributes to the network weights.
Entropy:
- Degree of uncertainty used to determine when to add randomness to the policy distribution.
Discount Factor:
- Determines how much of future rewards are discounted in calculating the reward at a given state as the average reward over all the future states. (0 -> current state is independent of future state, 1-> contribution from all future steps are included.)
Loss type:
- Objective function used to update the network weighs.
- Objective: from randon to strategic actiobs to increase the reward.
Responsible AI
Responsible Generative AI: A Code of Ethics for the Future
References:
- A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes
- The Ultimate Battle of Language Models: Lit-LLaMA vs GPT3.5 vs Bloom vs …
- SageMaker JumpStartModel API Docs
- Video: A Survey of Techniques for Maximizing LLM Performance, by OpenAI DevDay
- Mixture of Experts Explained, By HuggingFace
- Yann Lecun, New York University & META Title: Objective-Driven AI: Towards AI systems that can learn, remember, reason, and plan, video, ppt
- IEEE Spectrum - 15 Graphs That Explain the State of AI in 2024 The AI Index tracks the generative AI boom, model costs, and responsible AI use https://spectrum.ieee.org/ai-index-2024