👶 AI Agents Revolution
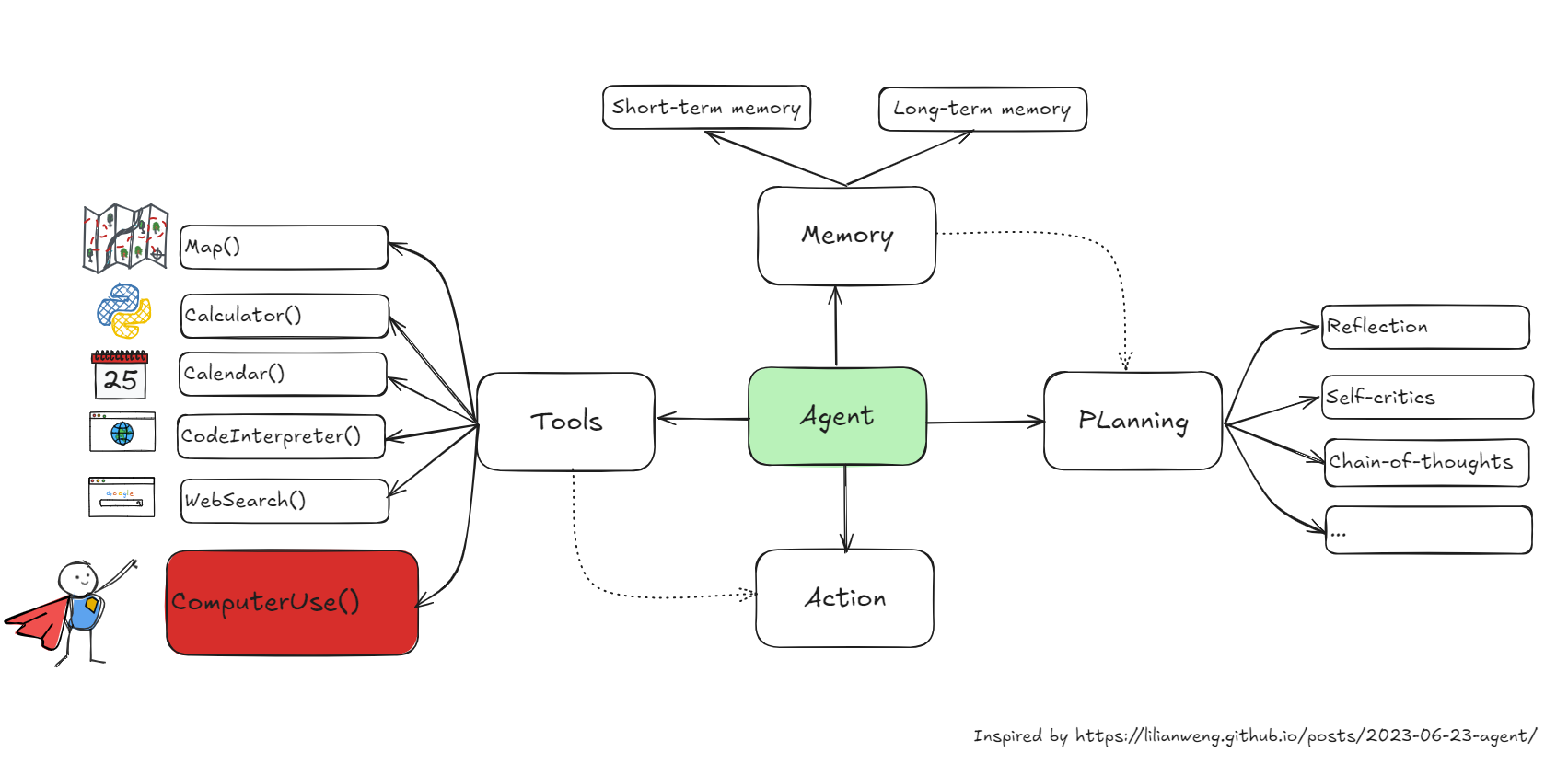
In the context of Large Language Models (LLMs), AI Agents are autonomous software entities designed to extend the capabilities of LLMs.
Recently , we have seen several agent frameworks such as AutoGen, CrewAI and LangGraph and examples such as AutoGPT and BabyAGI.
These solutions leverage LLM capabilities and typically consist of the following steps:
- 📄 Task decomposition: break complex tasks into smaller, manageable steps.
- ⚒️ Tool integration: LLM interacting with various tools and APIs to gather data from the environment, such as web scraping tools, calculator and python interpreter.
- 📚 Memory: used to retain information from past interactions, allowing to provide more context information.
- 💱 Autonomous execution: once plan is established, the agent can execute the steps autonomously.
These steps make AI agents powerful as they extend the functionality of LLMs beyond simple generation tasks towards autonomous task execution. For example, ReAct (Reasoning and Acting) is a common methodology applied to AI agents to improve performance by leveraging reasoning and acting capabilities.
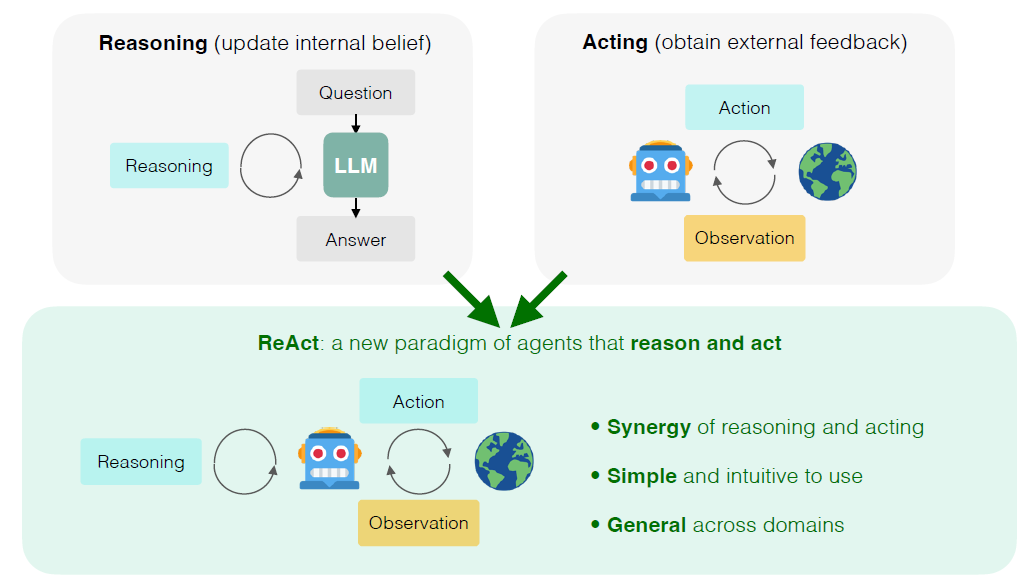
Picture by Shunyu Yao - LLM Agents - Brief History and Overview
❓ What has changed?
So far, AI agent frameworks have needed to communicate with the outside world through tool integration in the form of APIs. However, today Anthropic announced a new approach—LLMs performing tasks directly on your computer.
This is possible using computer use capability available in Claude 3.5 sonnet and Claude 3.5 Haiku.
Available today on the API, developers can direct Claude to use computers the way people do—by looking at a screen, moving a cursor, clicking buttons, and typing text. Claude 3.5 Sonnet is the first frontier AI model to offer computer use in public beta. At this stage, it is still experimental — at times cumbersome and error-prone. We’re releasing computer use early for feedback from developers, and expect the capability to improve rapidly over time.
According to Anthropic, instead of creating specific tools to help Claude complete individual tasks, we’re teaching it general computer skills—allowing it to use a wide range of standard tools and software programs designed for people.
Examples of Anthropic’s computer use capability include:
- Creating an entire website on the user’s computer and even fixes bugs in the code [here].
- Using data from user’s computer and online data to fill out forms [here].
- Orchestrating a multi-step task by searching the web, using native applications, and creating a plan with the resulting information [here].
Figure below shows the prompt for the example “Using data from user’s computer and online data to fill out forms” from youtube video: Computer use for automating operations.
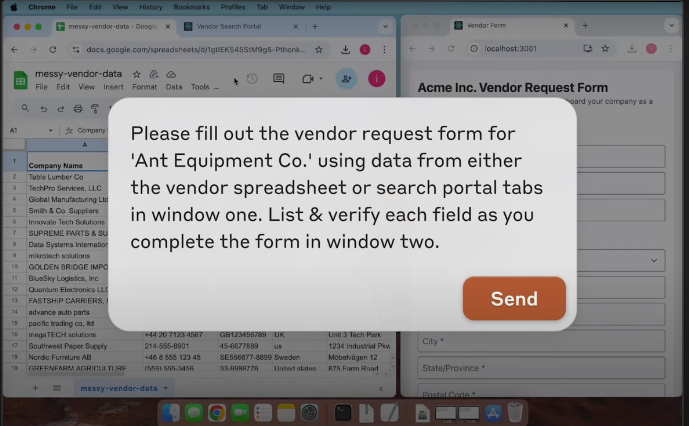
Picture by Anthropic’s new computer use tool from Youtube Computer use for automating operations video.
🔭 Things to Consider while building AI Agents that works
This section is based on my notes from the presentation given by Manjeet Singh, Salesforce on the SMALLCON conference by Predibase in Dec. 2024.
Important things to consider while building Production-ready AI agents based on steps provided above:
- 📄 Task decomposition: Topics
- ⚒️ Tool integration: Sources, knowledge quality, guardrails
- 📚 Memory: User context, page context
- 💱 Autonomous execution: actions, intent, latency
In addition, as highlight by Manjeet Singh, Salesforce customer trust on the agent is important, and common points below need to be considered:
❗ Data privacy and security concerns: e.g. legal
❗ lack of confidence in accuracy: “how this will behave in production? I am getting different answer each time”
❗ negative past experience: “I tried before and it did not work”
❗ ROI and cost concerns: “how to calculate business value?”
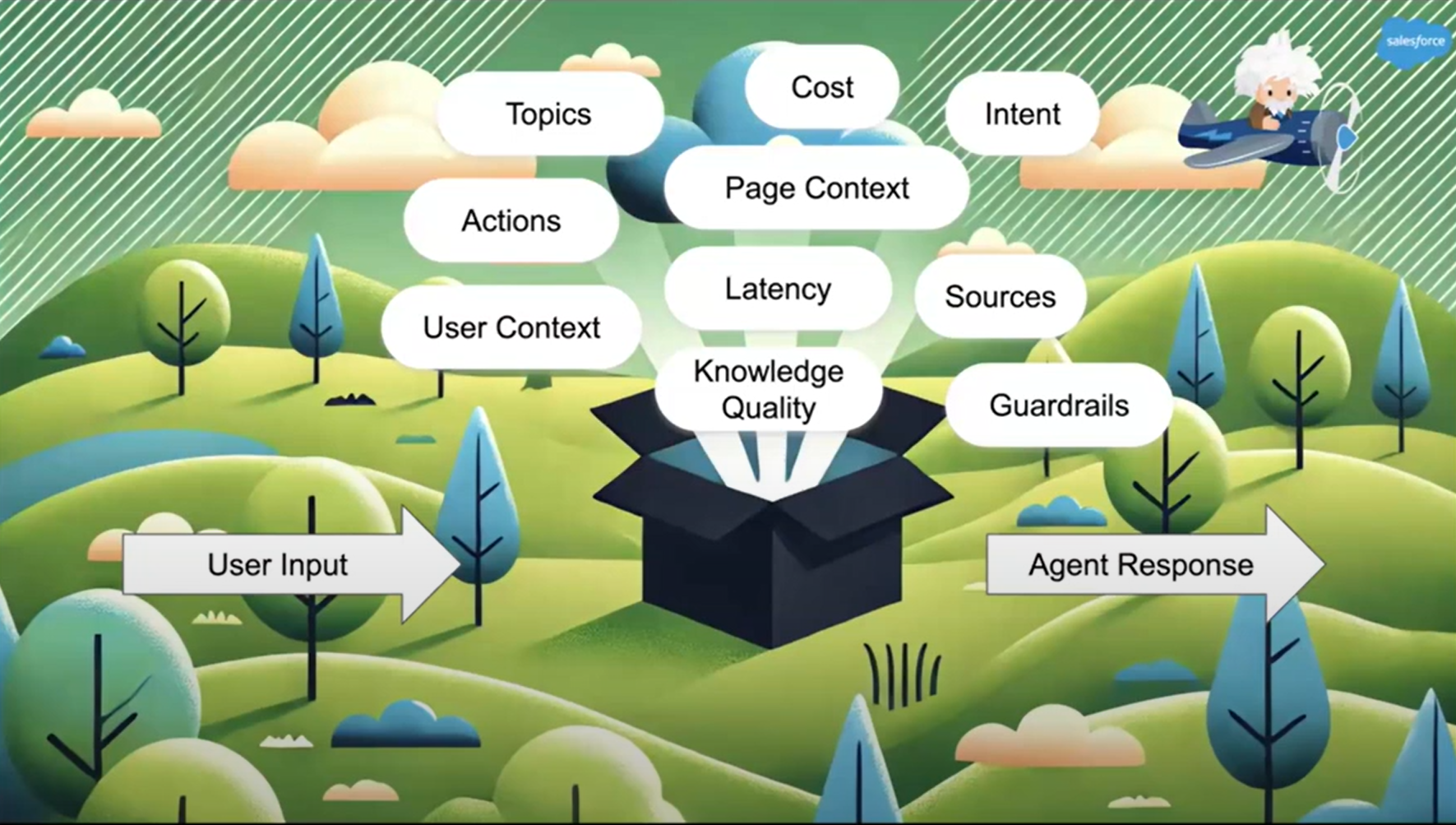
Picture by Manjeet Singh, Salesforce
As in in software development best practice, the agent development follows similar steps, which are:
➡️ Ideate ➡️ Setup ➡️ Configure ➡️ Test ➡️ Deploy ➡️ Monitor 🔁
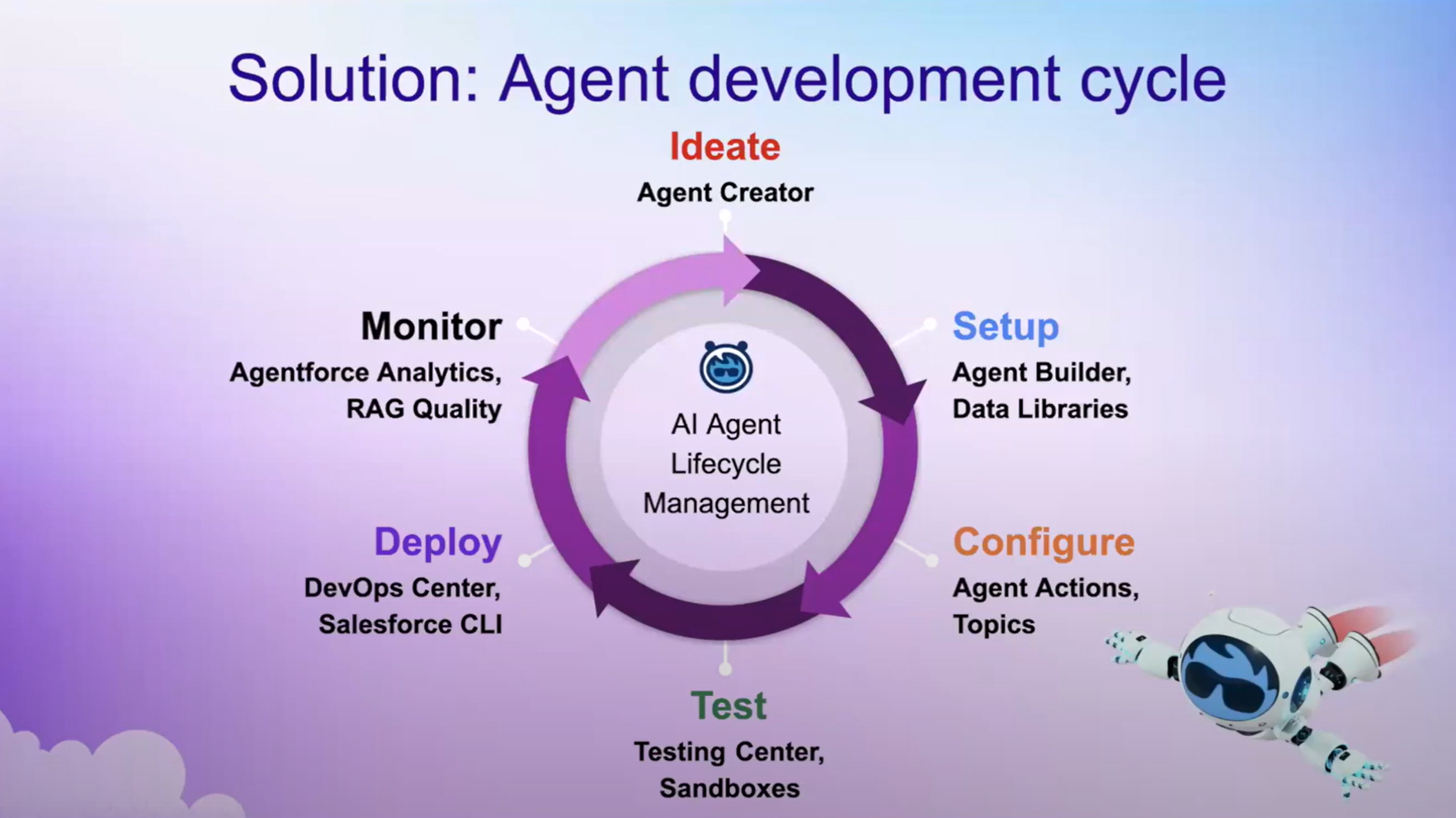
Picture by Manjeet Singh, Salesforce
⚒️ Test: toolset you need
Testing and evaluation during agent application development is very important.
As in all generative AI usecase, the journey normally looks like this:
➡️ Select a pre-trained LLM (e.g. gpt-4o or claude 3.5)
➡️ Prompt Engineering (improve prompt with few shots)
➡️ Prompt Engineering + RAG (longer prompts, slower inference)
➡️ Advanced techniques (advanced RAG, finetuning - improve speed, quality and cost)
Here is an example from Manjeet Singh, Salesforce to atomate agent evaluation.
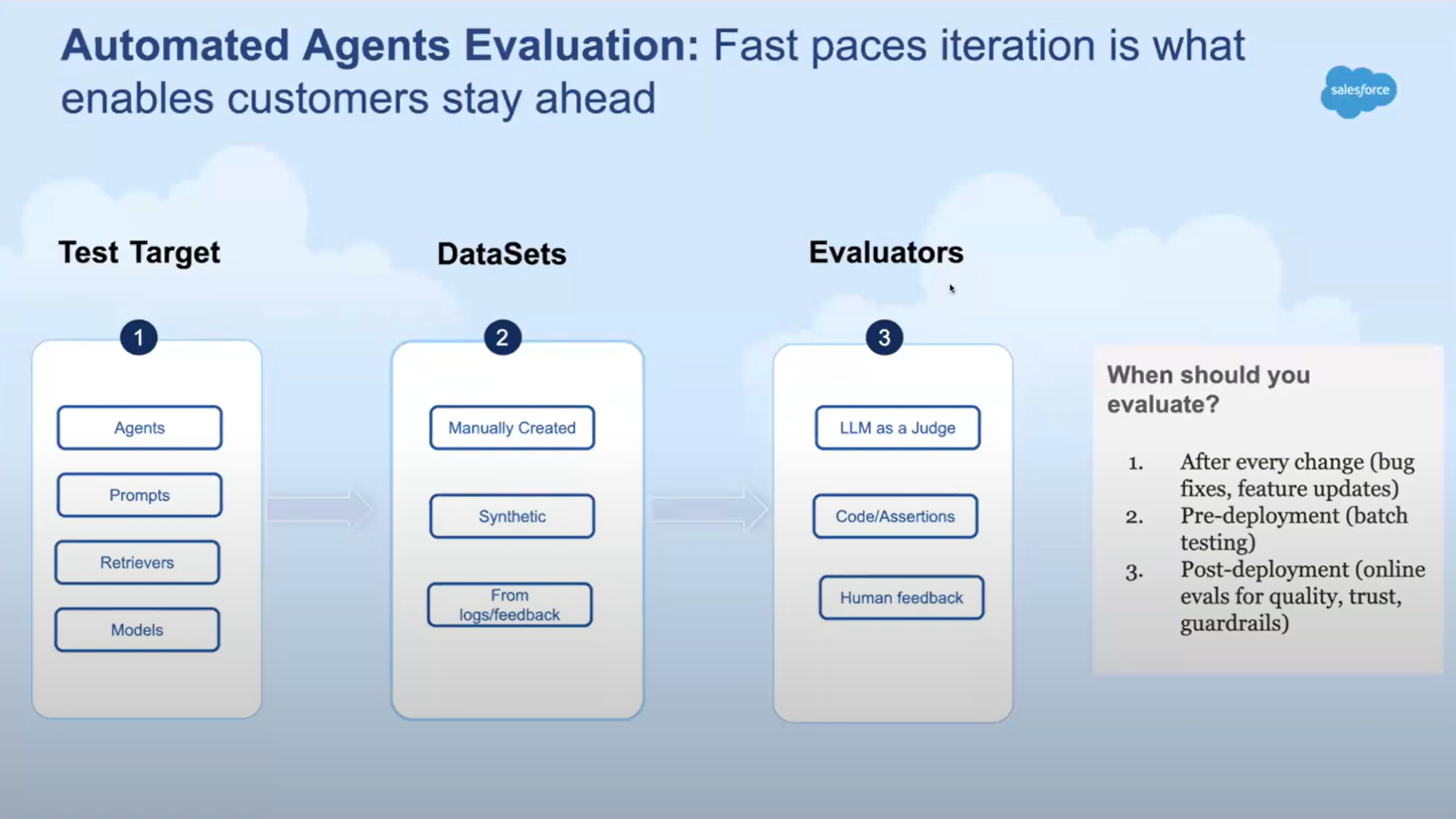
Picture by Manjeet Singh, Salesforce
Below is an example of evaluation while considering a RAG (Retrieval Augmented Generation) pipeline.
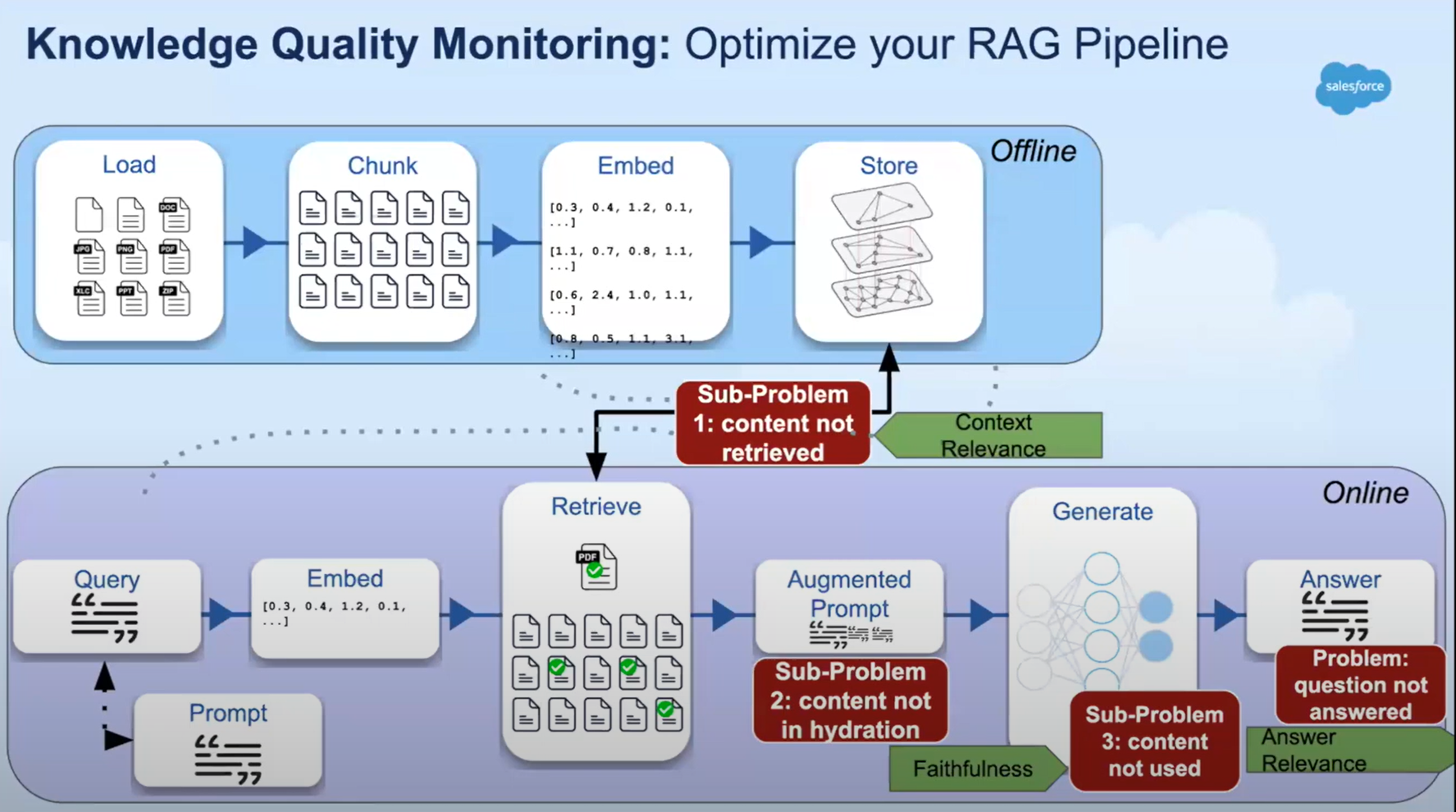
Picture by Manjeet Singh, Salesforce
👩🏫 How good are those agents today?
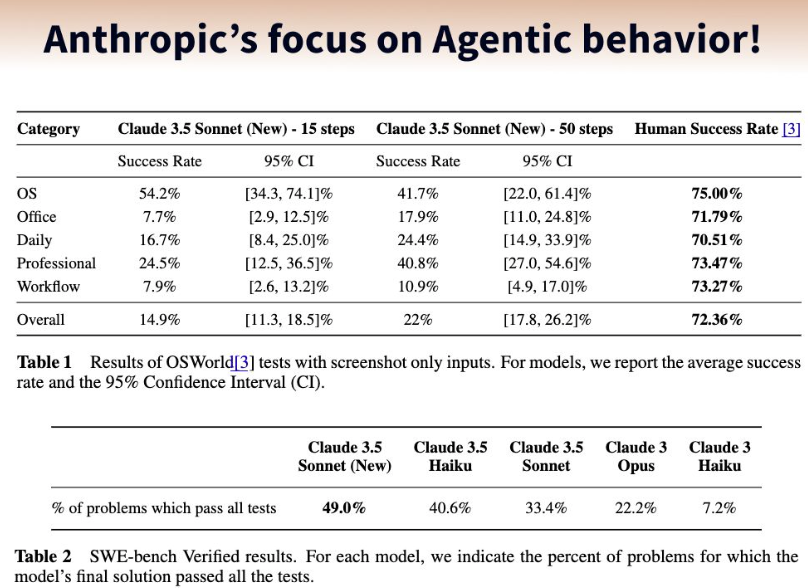
Picture by Philipp Schimid
References:
- AI Agents: Key Concepts and How They Overcome LLM Limitations by TheNewStack
- Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku by Anthropic (20241022)
- Berkley Course: Large Language Model Agents by Dawn Song
- The AI agents have arrived by Casey Newton
- When you give a Claude a mouse by Ethan Mollick
- LLM Powered Autonomous Agents | Lil’Log
- Agents by Chip Huyen