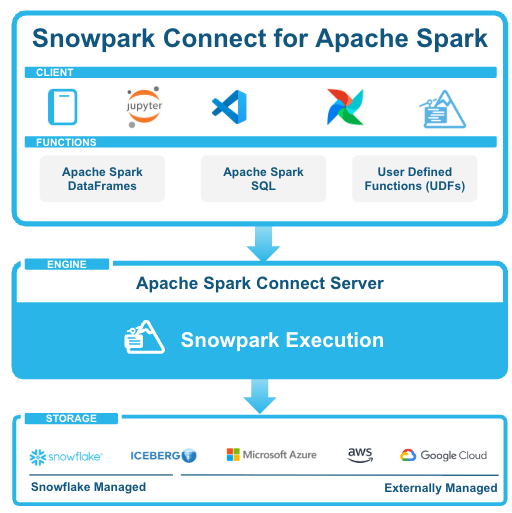
# Snowflake Connection Setup for Cursor/Jupyter
import os
from dotenv import load_dotenv
from snowflake.snowpark import Session
# from snowflake import snowpark_connect # Not available in standard installations
# Load environment variables from .env file
load_dotenv()
# Connection parameters - Update these with your Snowflake credentials
# connection_parameters = {
# 'account': os.getenv('SNOWFLAKE_ACCOUNT', 'your_account_identifier'),
# 'user': os.getenv('SNOWFLAKE_USER', 'your_username'),
# 'password': os.getenv('SNOWFLAKE_PASSWORD', 'your_password'),
# 'role': os.getenv('SNOWFLAKE_ROLE', 'SYSADMIN'),
# 'warehouse': os.getenv('SNOWFLAKE_WAREHOUSE', 'COMPUTE_WH'),
# 'database': os.getenv('SNOWFLAKE_DATABASE', 'AICOLLEGE'),
# 'schema': os.getenv('SNOWFLAKE_SCHEMA', 'PUBLIC')
# }
# Alternative: Import from config file
from snowflake_config import SNOWFLAKE_CONFIG
connection_parameters = SNOWFLAKE_CONFIG
try:
# Create Snowpark session
session = Session.builder.configs(connection_parameters).create()
# Note: We'll use Snowpark DataFrames instead of Spark DataFrames
# Snowpark provides similar functionality to Spark for data processing
print("✅ Connected to Snowflake successfully!")
print(f"Current database: {session.get_current_database()}")
print(f"Current schema: {session.get_current_schema()}")
except Exception as e:
print(f"❌ Connection failed: {str(e)}")
print("Please check your Snowflake credentials in snowflake_config.py or .env file")--------------------------------------------------------------------------- ModuleNotFoundError Traceback (most recent call last) Cell In[3], line 22 8 load_dotenv() 10 # Connection parameters - Update these with your Snowflake credentials 11 # connection_parameters = { 12 # 'account': os.getenv('SNOWFLAKE_ACCOUNT', 'your_account_identifier'), (...) 20 21 # Alternative: Import from config file ---> 22 from snowflake_config import SNOWFLAKE_CONFIG 23 connection_parameters = SNOWFLAKE_CONFIG 25 try: 26 # Create Snowpark session ModuleNotFoundError: No module named 'snowflake_config'