✨ DeepSeek-R1 and the “aha-moment” ✨
DeepSeek-R1 is the latest large language model from the Chinese company DeepSeek. This model showcase a significant leap in AI capabilities. Unlike traditional models that rely heavily on supervised fine-tuning (SFT) to get started, DeepSeek-R1 uses large-scale Reinforcement Learning (RL) to boost its reasoning skills. This innovative approach allows DeepSeek-R1 to perform on par with top closed models like OpenAI-o1-1217, without needing extensive pre-training.
DeepSeek-R1’s multi-stage training pipeline, which includes using cold-start data before RL, sets it apart from its predecessors. By incorporating reasoning tokens during inference, DeepSeek-R1 can generate smarter responses, making it a powerful tool for tackling complex reasoning tasks. This model not only shows the potential of RL in enhancing AI performance but also paves the way for future advancements in the field.
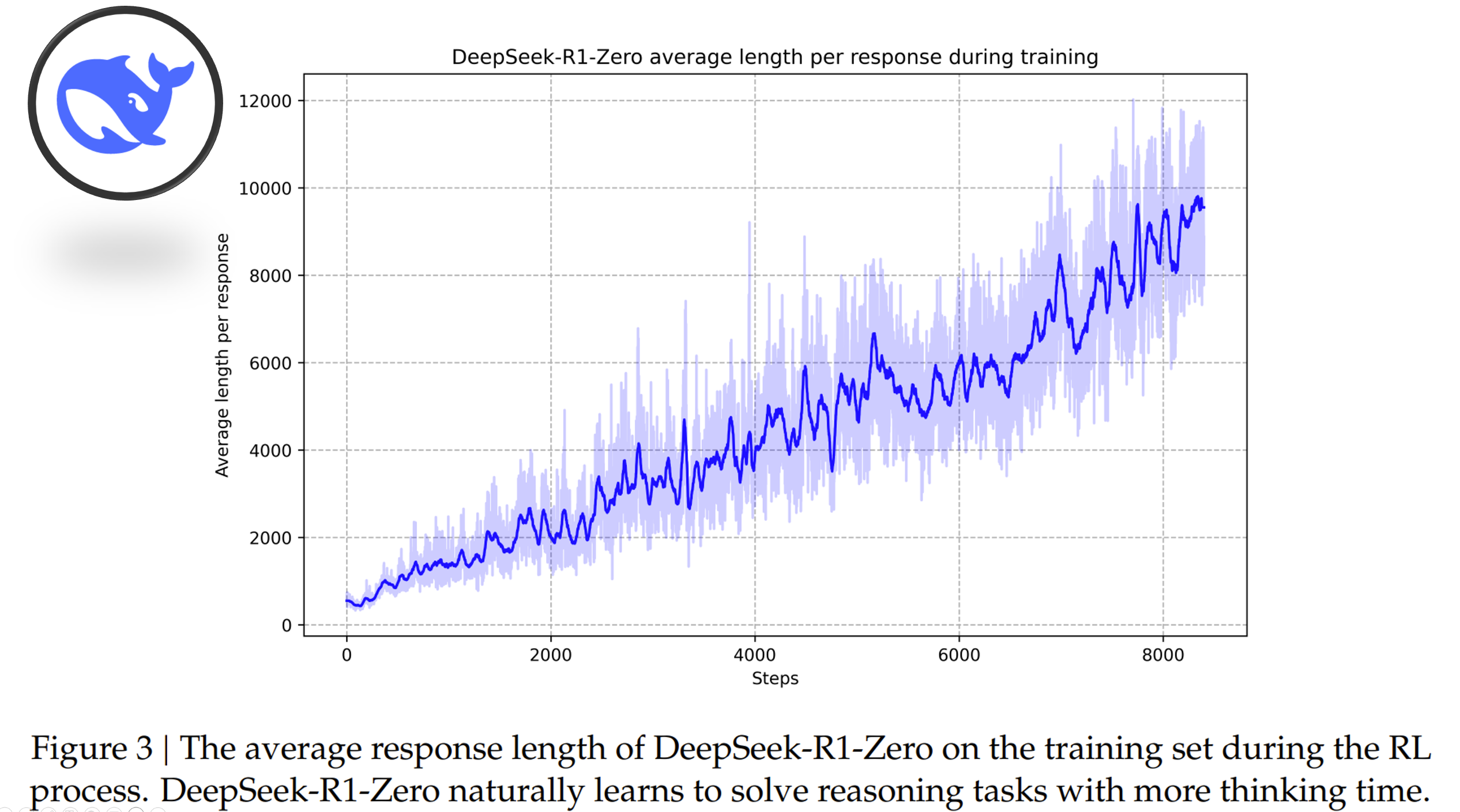
DeepSeek-R1: more intelligence via inference-time scaling through increasing the length of the Chain-of-Though reasoning process.
The figure below illustrates DeepSeek-R1’s ability to solve complex reasoning tasks by leveraging extended test-time computation. More steps represent more thinking, allowing the model to explore and refine its thought process in greater depth.
🧠 The art of reasoning tokens
Reasoning tokens (also named thinking tokens) enables more intelligence to large models during inference. Until now, the rule to get more intelligent models was only possible through pre-training large model following the “scaling laws”, i.e. adding more training data and computing to pretrain large models.
Now with the concept of “reasoning tokens” you can achieve more intelligence with the introduction of a model reasoning while doing the next token prediction. This concept has been introduced by Quiet-STaR, OpenAI o1, QnQ and latest DeepSeek-R1.
<|startofthought|> and <|endofthought|> or
as in DeepSeek-R1
The basic concept is to generate “thinking tokens” at inference time to help model to predict next token. A key challenge is to efficiently generate rationales at each token position in the input sequence.
🤔 What is DeepSeek-R1
DeepSeek-R1 is the based on the DeepSeek-R1-Zero model which is the DeepSeek-v3-base model with large scale RL without SFT. DeepSeek-R1-Zero encountered challenges in relation to poor readability and language mixing. DeepSeek-R1 address this issue by incorporating multi-stage training and cold-start data before RL.
The figure below illustrate the main building blocks used to derive DeepSeek-R1.
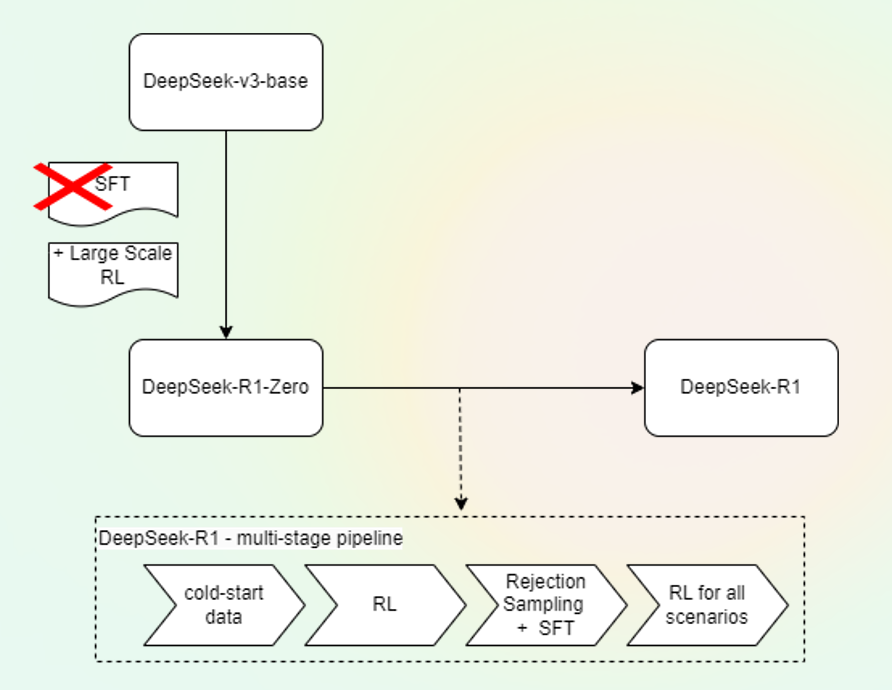
The multi-stage pipeline is composed by the following steps:
- Several thousands of cold-start Chain of Thought (CoT) data to fine-tune the base model.
- Reinforcement Learning stage using GPRO and similar to DeepSeek-R1-Zero.
- A SFT through rejection sampling data plus supervised data from DeepSeek-v3 in domains such as writing, factual QA and self-cognition -> ~600k data points.
- Additional RL with prompts in order to make the model harmless and helpful.
The cold-start are long Chain-of-through data used to fine-tune the model. Cold-start data brings readability advantages by including a summary at the end of each response and filtering out responses that are no reader-friendly following the pattern: |speacial_token |
The Reinforced Learning (RL) technique used is named GRPO (Group Relative Policy Optimization). Unlike traditional RL methods which rely heavily on external evaluators (critics) to guide learning, GRPO optimizes the model by evaluating groups of responses relative to one another.
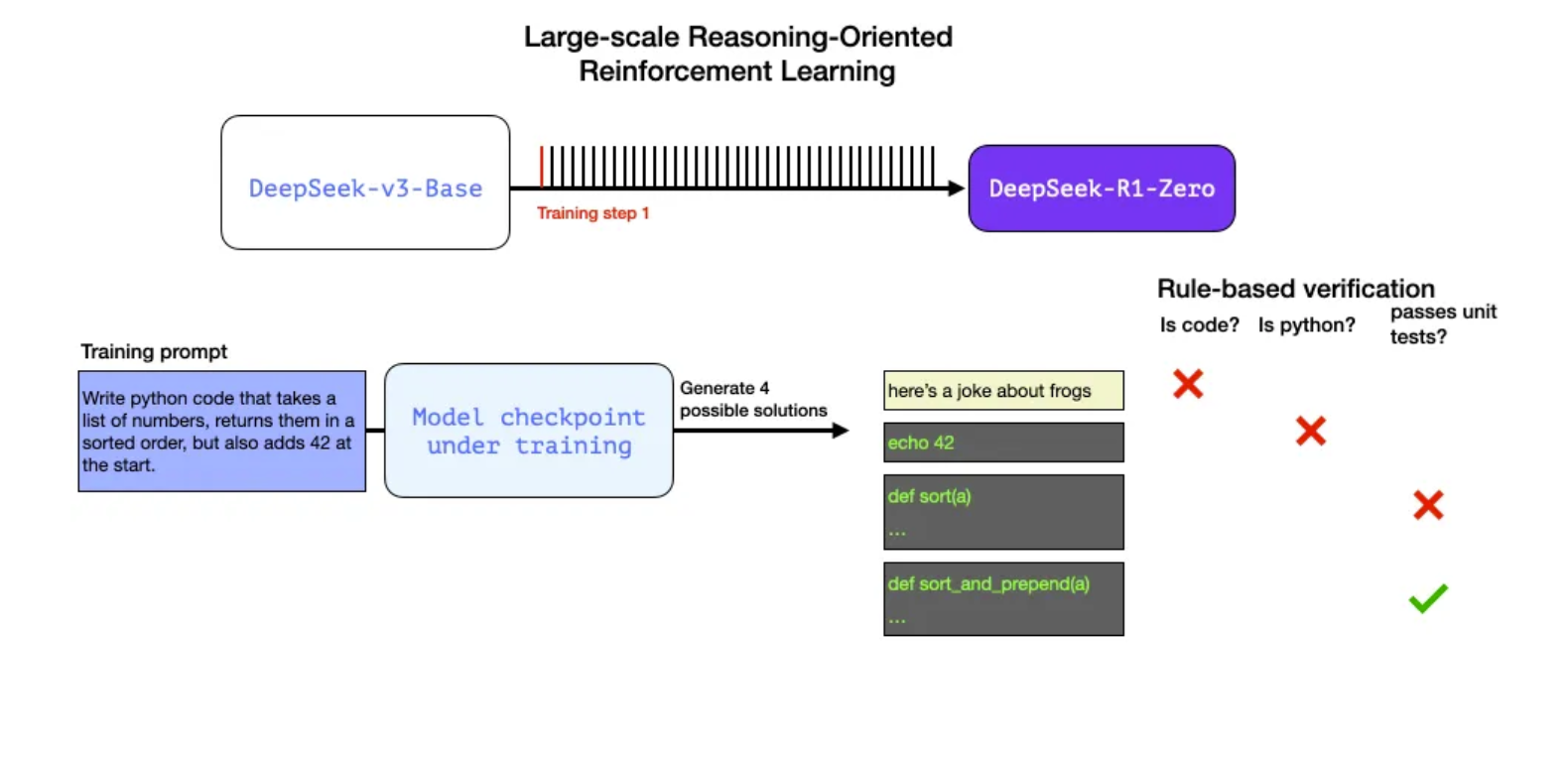
GRPO mainly uses 2 reward functions:
accuracy rewards: which evaluates whether the response is correct. (e.g. math problem with deterministic results and final answer, unit tests for code as accuracy computation).
format rewards: which enforces thinking process by rewarding model if it separates the “thinking” and the “answer” parts by
tags.
The figure below by Jay Alammar, provides an excellent illustration example of such RL technique using reward signals. More information on GRPO on the paper DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.
💡 The “aha moment” :
The model self-evolution through RL indicates its capability to reflect by revisiting and reevaluating previous steps and exploring alternative approaches through problem solving by using extended test-time computing during reasoning.
“The self-evolution process of DeepSeek-R1 is fascinating as it demonstrate how RL can drive the model to improve its reasoning capabilities autonomously. By initiating RL directly from the base model, the author could monitor model progression without the influence of the supervised fine -tuning stage - indicating how model evolves overtime and its ability to handle complex reasoning tasks by leveraging extended test-time computing.”
In addition to RL, DeepSeek-R1-Zero can be further augmented through the application of majority voting.
📝 Rejection sampling and SFT
Rejection sampling and SFT is applied using data from other domains to enhance the model’s capability in writing, role-playing and other general-purpose tasks. For reasoning data this is done using generative reward model with ground-truth and DeepSeek-v3 as a judge (i.e. 600k reasoning training samples in total). For non-reasoning data such as writing, factual QA, self-cognition and translation, the DeepSeek-v3 pipeline is used including reuse of portions of the SFT dataset of DeepSeek-v3 (200k training samples in total).
🌐 RL for all scenarios
RL is used to further align the model with human preferences through a secondary RL stage to improve model helpfulness and harmlessness. Rule-based rewards is used to guide the learn process in math, code and logical reasoning domains, using the same distribution of preference pairs and training prompts used by DeepSeek-v3 pipeline.
🧪 Distilled Models:
Fine-tuning is used as a distillation method to empower small models with reason capabilities like DeepSeek-R1. DeepSeek released 6 dense models (1.5B - 70B range) based on Qwen/Llama and distilled from DeepSeek-R1 using 800k curated samples. For distilled modes only SFT is applied (no RL stage included).
🔍 Other interesting points:
- Despite advocating that model distillation are both economical and effective methods, the DeepSeek’s authors highlight that advancements beyond the boundaries of intelligence may still require powerful base models and large-scale RL.
- Monte Carlo Tree Search (MCTS), which is used by AlphaGo and AlphaZero, has also been proposed as a technique to enhance test-time compute scalability. But DeepSeek’s authors has seen scaling limitation during training as token generation presents an exponentially large search space compared to chess.
- DeepSeek-v3-base is used as the base model for DeepSeek-R1 and follows a Mixture of Expert (MoE) architecture. It has 671 billion parameters where 37 billion is activated for each token. See my previous post Understanding Mixture of Expert for additional information on MoE architectures.
- DeepSeek-v3-base uses Multi-Head Latent Attention (MLA) as its attention mechanism. MLA proposes a low-rank joint compression for the attention keys and values in order to reduce KV (Key-Value) cache during inference. See the Multi-Head Latent Attention section in my post The Power of Focus: Understanding Attention Mechanisms in LLM for more information and references.
🚀 Conclusion: The Future Implications of DeepSeek-R1 in AI
DeepSeek-R1 shows how large-scale Reinforcement Learning (RL) can improve reasoning without extensive supervised fine-tuning (SFT). By using multi-stage training and cold-start data, DeepSeek-R1 matches the performance of top models.
Key points highlighted in this article include:
- Multi-stage Training: Combining cold-start data, RL, and SFT to enhance the model.
- Reinforcement Learning: Using Group Relative Policy Optimization (GRPO) to improve responses.
- Reasoning Tokens: Generating “thinking tokens” to boost reasoning.
- Self-Evolution: The model improves itself through RL.
- Distilled Models: Smaller models gain similar reasoning abilities through fine-tuning.
DeepSeek-R1’s success highlights the potential of RL and reasoning tokens for creating smarter AI. This model opens new possibilities for AI applications in various fields, from language processing to decision-making.
📚References:
- DeepSeek-R1 Technical Report
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning by DeepSeek-AI
- The Math Behind DeepSeek: A Deep Dive into Group Relative Policy Optimization (GRPO) by Ahmed
- The Ilustrated DeepSeek-R1 by Jay Alammar
- Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
[!TIP]
For a fully open reproduction of DeepSeek-R1, check Open R1 project by Hugging Face.
By the way you can use the DeepSeek’s AI assistant app in the Apple App Store.